SQL Server Pivot 行转列的使用研究
大家制作报表或使用 SQL 进行数据处理时,如果能够利用 Pivot 对数据进行行转列加工,往往会起到意想不到的效果。下面具体讲解一下 Pivot 如何实现数据行转列。
一、数据准备
- 创建学生成绩表

- 原始数据
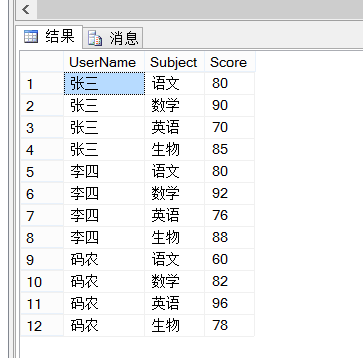
- 拟实现数据效果
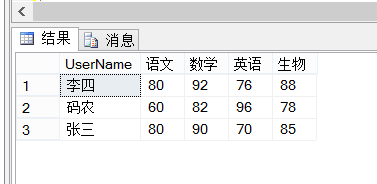
二、具体 SQL 研究
SELECT * FROM [StudentScores] /数据源/ AS P PIVOT (SUM(Score/行转列后 列的值/) FOR P.Subject/需要行转列的列/ IN ([语文],[数学],[英语],[生物]/列的值/)) AS T
首先,大家要从逻辑上把上面的 SQL 语句分成两部分;FROM 关键字之后看成一个整体,对应行转列之后的数据集且别名为 T(必须要起别名)。这时,SELECT 子句只能获取数据集 T 中的字段。
以上面的 SQL 语句为例作分析,FROM 子句形成的数据集 T 中有哪些字段呢?
包括 UserName, [语文], [数学], [英语], [生物]。注意:由行转列生成的字段必须加中括号。
那数据集 T 中的字段又是怎么形成的呢?
首先表 [StudentScores] 中的所有字段作为原始加工素材。除去与行转列有关的 Score 与 Subject 字段,表 [StudentScores] 中的其他字段都作为数据集 T 中的字段。
其次,Subject 字段值(即 IN 关键字之后的部分)也变成了数据集 T 中的字段,例如上面的 [语文],[数学],[英语],[生物]。
三、SQL 语句扩展
SELECT * FROM (SELECT UserName, Subject, Score FROM [StudentScores] WHERE UserName=’张三’) /*数据源*/
AS P
PIVOT
(
SUM(Score/*行转列后 列的值*/) FOR
P.Subject/*需要行转列的列*/ IN ([语文],[数学],[英语],[生物]/*列的值*/)
) AS T
本段 SQL 语句与上面的 SQL 语句的区别在于,形成行转列数据集 T 的原始加工素材发生了变化。上面的 SQL 语句是对表 [StudentScores] 中的所有字段和数据进行加工;而本段 SQL 语句是对子查询数据集中的所有字段和数据进行加工。所以总结如下:Pivot 关键字前的数据集是原始加工素材,进行行转列后得到一个新的数据集且必须有表别名。
假如 SQL 语句变成上面的写法,结果会有什么样的变化呢?大家可以一试。